Spark Queries That Take Hours.
Now Done in Minutes.
TabbyDB is a drop-in fork of Apache Spark that eliminates compile-time blowup, OutOfMemory failures, and nested join underperformance — at the optimizer level. Zero code changes. Zero cluster changes.
The Real Bottleneck Is in Apache Spark
Production workloads hit walls that benchmarks never reveal. Compile time, optimizer failures, and bad workarounds compound silently until it's too late.
Root Cause: Query Planning
Compile time can take minutes to hours — but Spark's UI only registers a query after plan submission. The bottleneck is in planning, not execution, and it's invisible to your metrics.
Why Tuning Fails
Compile-time problems are routinely misdagnosed as runtime issues. Runtime tuning doesn't reduce planning time. More compute doesn't mean faster planning. The fixes you try don't touch the root cause.
Workarounds Backfire
Disabling optimizer rules can reduce compile time — but at the cost of runtime performance. Every workaround forces a tradeoff: faster planning vs. slower execution. TabbyDB eliminates this tradeoff.
The result: minutes to hours of delay, wasted compute, and missed SLAs — with no clear path to fix it in stock Spark.
TabbyDB — Turbocharged Apache Spark
A strict superset of Apache Spark 4.0.1 and 4.1.1. Same APIs. Same clusters. Better engine. Drop in the jars and get back hours.
Intelligent Compile-Time Optimizations
Fundamental improvements to critical optimizer rules: optimized constraint propagation, early project collapsing during analysis, reduced Hive Metastore calls, and targeted rule application to avoid expensive tree traversals. Complex queries that took 8 hours now compile in minutes.
Scalable Query Tree Management
Safely collapses project nodes early in the query lifecycle, preventing unbounded query plan growth and reducing memory pressure during compilation. Faster compilation and dramatically reduced risk of out-of-memory failures on deeply nested workloads.
Advanced Broadcast Hash Join Handling
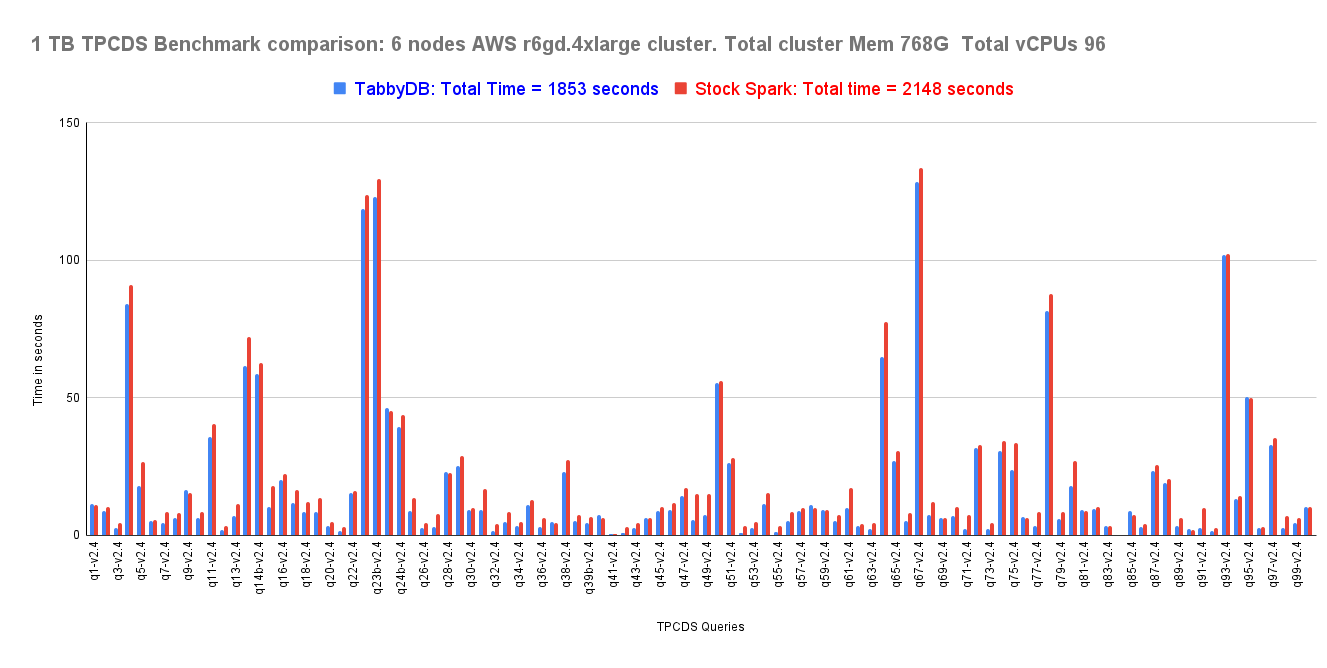
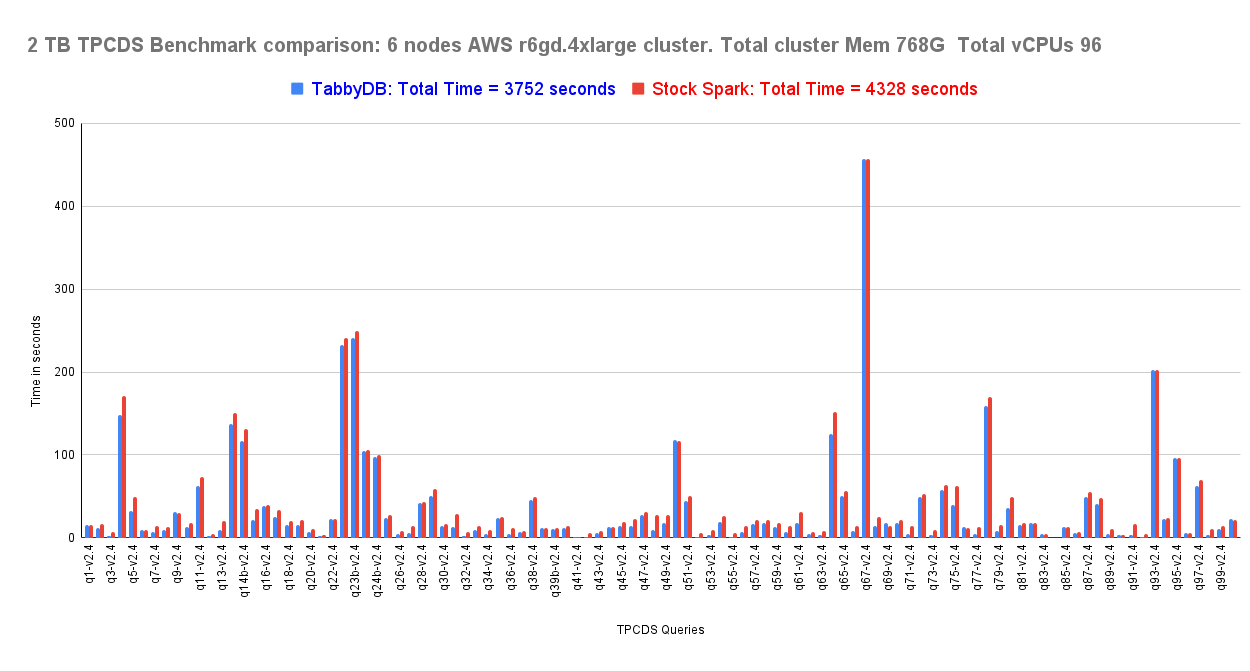
Dynamic file pruning using Broadcast Hash Join data on non-partitioned columns — the fix Spark never shipped. Extended to enable dynamic file pruning for non-partitioned joins, reducing data scan time. 13% improvement on TPC-DS at 1TB and 2TB.
Improved Cache Lookup Efficiency
Enhances how cached in-memory query plans are matched and reused, increasing the likelihood of successful cache hits. Higher cache reuse and lower execution overhead — especially for repeated or structurally similar queries.
Apache Iceberg — 46%+ Faster
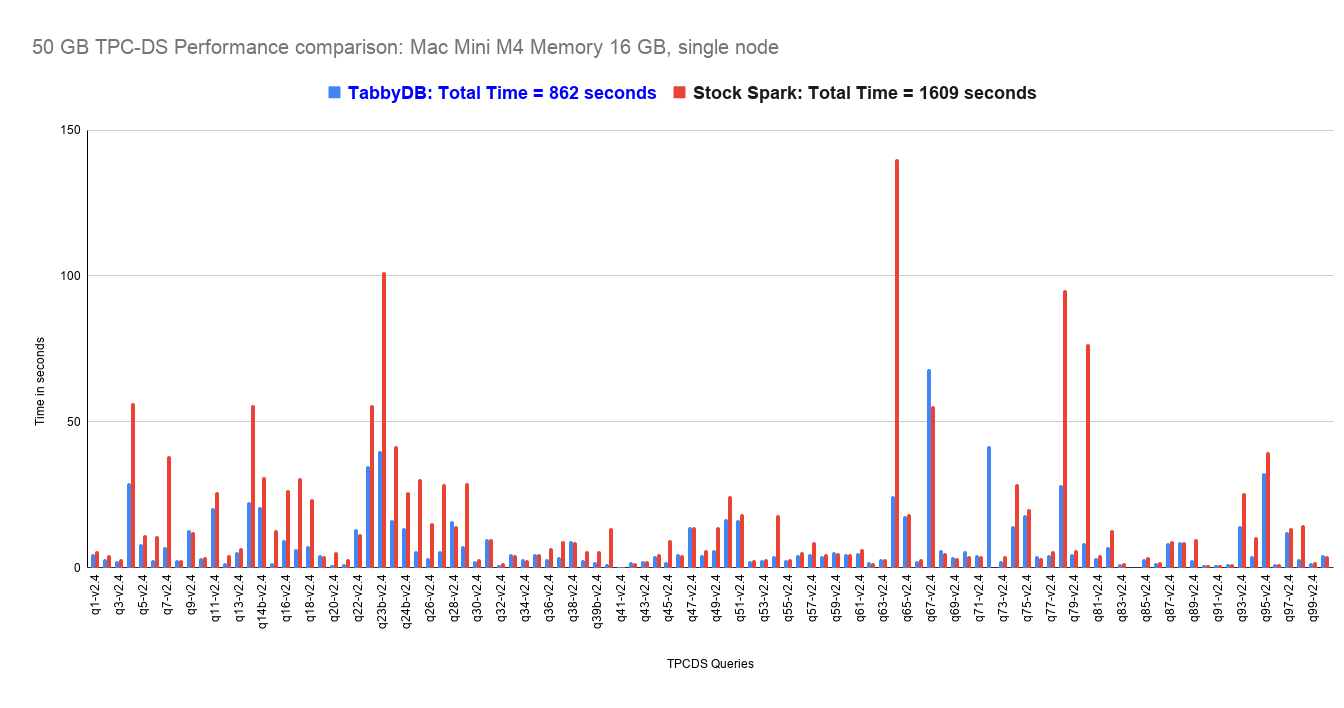
Early testing on 50GB non-partitioned Iceberg tables shows 46% improvement. Gains are expected to grow beyond 46% at 1TB–2TB scale. The Iceberg performance layer the ecosystem has been waiting for.
Seamless Spark Compatibility. No Lock-In.
Maintains full compatibility with Apache Spark APIs, features, and tooling while delivering every performance improvement above. Replace Spark jars with TabbyDB jars. To revert: swap back. No code rewrites. No cluster changes. No disabling of optimizer rules.
Performance That Redefines Complex Query Execution
1TB & 2TB on AWS r6gd.4xlarge — non-partitioned Hive Parquet tables
50GB non-partitioned tables. Gains expected to increase at 1TB–2TB scale
Complex DataFrame API queries — hours to compile, now minutes
TPC-DS gains shown on non-partitioned tables. Standard TPC-DS (partitioned) shows equivalent performance to stock Spark by design.
See the performance difference for yourself. Click below to open our Zeppelin notebooks, where you can run the same query on both Stock Spark and TabbyDB side by side. Note: running the Stock Spark paragraph may take 5–12 minutes.
Compare Performance Now →TPC-DS Benchmark Results
Spark SQL Modules Optimized in TabbyDB


20+ Apache Spark JIRA Issues — Resolved
More Than a Faster Engine
TabbyDB is built for teams running complex, production-critical Apache Spark workloads, where query compilation time, optimizer behavior, and correctness matter as much as execution speed.
Engine-Level Enhancements
Improvements are made at the optimizer and execution engine level — not as application-layer patches. This means every workload benefits, without requiring any tuning or code changes.
Built for Stability & Correctness
Beyond raw performance, TabbyDB addresses 20+ long-standing Spark correctness issues — self-join inconsistencies, data loss in POJO conversions, broken idempotency in streaming joins. Stability and predictability matter as much as speed.
Compatible With Everything You Have
TabbyDB maintains full compatibility with existing Spark APIs, tooling, and workflows. No migration. No vendor lock-in. If you ever need to roll back, swap the jars.
Partner With the Team Behind TabbyDB
If you are encountering functional or performance issues in Apache Spark — particularly within the SQL or optimizer layer — we're open to collaborating on solutions tailored to your workload or codebase.
Whether it's diagnosing a bottleneck, validating a fix, or contributing targeted improvements or customizations, we're happy to engage.
Try TabbyDB on Your Actual Workloads
Speak with our experts to get a solution tailored to your business goals and data needs. We help you plan the right strategy for faster growth and better results.
Read the Algorithms
Every optimization in TabbyDB is documented. Read the white paper before you decide. Then run the benchmark.
Constraint Propagation Rule Optimization
The new algorithm that solves Constraint blow-up from permutational logic in stock Spark.
PerformanceCapping the Query Plan Size
Collapsing project nodes in the analysis phase to prevent tree size explosion in complex DataFrame API queries.
Compile TimeBroadcast Hash Join Key Pushdown
Dynamic file pruning for non-partitioned columns — the runtime performance fix Spark never shipped.
RuntimeTPC-DS Benchmark Details
Full breakdown of methodology, configuration, and results for 1TB and 2TB benchmarks on AWS.
BenchmarksCommon Subexpression Extraction
Applying expensive optimizer rules only once to complex repeated sub-expressions — avoiding redundant tree traversal.
OptimizerLive in 15 Minutes. Revert in 30 Seconds.
Download TabbyDB jars (4.0.1 or 4.1.1)
Replace your existing Spark jars
Run your existing pipelines — unchanged
To revert to stock Spark: remove TabbyDB jars, restore Spark jars. No configuration changes. No code changes. No cluster changes.
Stop Waiting for Spark to Compile.
Download the trial. Run it on your actual queries. See the difference on your own cluster.
100% Apache Spark API compatible. No code changes. Full rollback in seconds.